A key part of any analysis is to determine the uncertainty associated with an estimate. Typically we use confidence intervals to show this. Sometimes deriving this can be tricky with certain methods or when assumptions aren’t met. For example, if we use propensity score matching and then fit a generalized linear model in this matched sample, the assumption about the cases being independent isn’t true. So what do we do? We need a different way to calculate the standard error. Enter bootstrapping!
NoteEstimating Variance
This post will focus on bootstrapping but it’s important to note that it’s not the only solution. For example, a commonly used way to calculate variance with PS methods is the robust variance estimator (Austin 2011). a
What exactly is bootstrapping?
No, not like Bootstrap Bill (Pirates of the Caribbean reference). Bootstrapping is a statistical technique that can be quite useful. It comes from the term “pull oneself up by their bootstraps” in the sense that we use our sample that we already have. We can use this to estimate confidence intervals! But can also use it for other things. So how exactly does it work?
How does it work?
Bootstrapping works by drawing repeated samples, with replacement aka putting the observations we drew back, from our sample. The idea is that by resampling the data we can use this to imagine what a new sample (of the same size) would look like if we drew from our population again.
The beauty about bootstrapping is all we need is an estimate and a sampling distribution (Gelman et al. 2020). A better way to understand it is with a quick example.
Imagine that you go to an ice cream store and order a bowl of ice cream. You get a bowl of ice cream that’s 80% vanilla and 20% chocolate but you’re curious what the big tub in the back of the store looks like. Is it mostly vanilla? Chocolate? Is it a 70/30 split of either? Are there other flavours? If you asked for another bowl from the same tub would you get the same proportion?
To try and determine this, you take a spoonful of ice cream randomly and put it in another bowl (of the same size). You do this over and over until you have a new bowl of ice cream. This is magical ice cream though, so once you take a spoonful, that same flavour and amount appears in the bowl again (aka it’s replaced, so it can appear more than once). This new bowl of ice cream is 60% chocolate and 40% vanilla. You put it back then do it all over again and notice it’s 80% vanilla and 20% chocolate. If you do this over and over again, you can use this to try and get an idea of what the big tub in the back looks like.
This is bootstrapping. We take samples, with replacement, to try to understand what the whole picture looks like. Let’s try another example with some actual numbers!
Mini-Golf?
Let’s use mini-golf as an example. Imagine that you play mini-golf with your friends 100 times over a summer (yes you must really REALLY love mini-golf). Each time you play, you get a different score (the lower the better). Sometimes you do well, sometimes you play awful.
You start to think: “I play a lot of mini-golf, but am I any good? What would my score be on average?” being the keen person that you are, you also wonder what kind of confidence intervals go with this average. So you decide to use bootstrapping to answer this, using these steps:
Draw 100 scores, from any day (randomly) and write them down. We are doing this with replacement, so the same observation can appear more than once.
Put them back.
Draw another 100 scores and write them down.
Put them back.
Repeat steps 1-4
Now we have our plan, let’s start implementing it!
Mini-Golf - Average Score
So we know our average score, if we just take the mean of all the scores. But what is the confidence interval for this mean? To calculate this we often use the standard error while assuming a normal distribution. But what is the standard error? Is it the same as the standard deviation? Not quite.
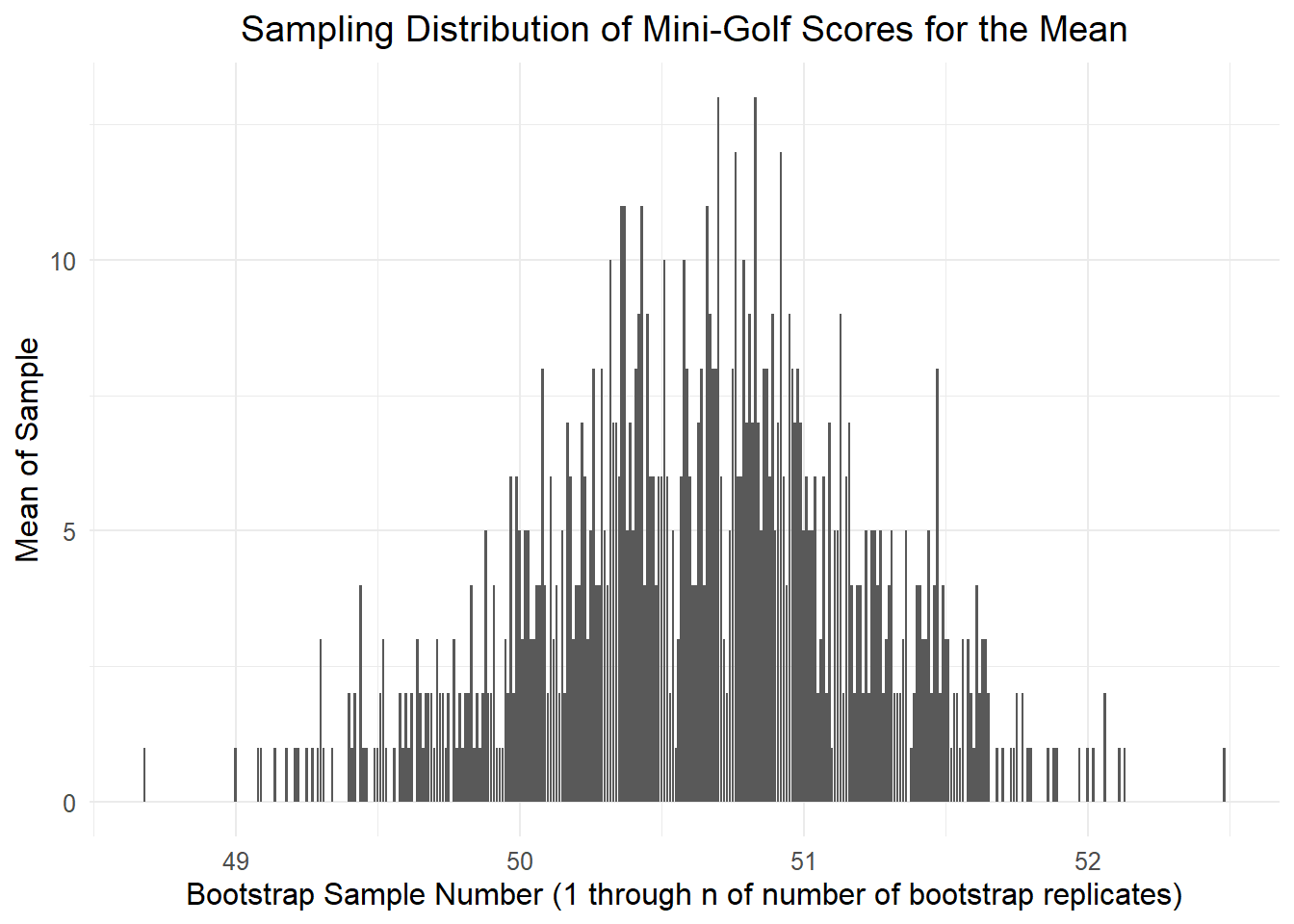
The standard error is the standard deviation of the sampling distribution. The sampling distribution is the probability distribution of a statistic. This may sound like a bit of jargon, so instead let’s use a visual.
For our example, we are taking 100 scores over and over. Each time we take 100 scores, we calculate the mean. So for each time, we have the mean. Let’s plot this!
Code
library(tidyverse) # Loading the tidyverse package# Setting seed for reproduceability, arbitrarily chosen in this caseset.seed(123)# Original mini-golf scores, one per day for 100 days. original_scores <-sample(40:60, 100, replace =TRUE)# Initalizing a variable to store the bootstrap estimates in bootstrap_estimates <-numeric()# Number of bootstraps. For this case, arbitrarily choosing 1000. In reality, need to consider what number to usen_bootstraps <-1000# Time to do the bootstrapping!for (i in1:n_bootstraps) {# Draw 10 samples from our original scores, with replacement. That # way you have the same sample each time bootstrap_sample <-sample(original_scores, size =100, replace =TRUE) # Calculate the mean for our new sample bootstrap_mean <-mean(bootstrap_sample)# Combine our new estimated mean bootstrap_estimates <-c(bootstrap_estimates, bootstrap_mean)}# We can calculate the 95% CI as either finding out the standard error (calculate the standard deviation of bootstrap_estimates) OR can use the corresponding quantiles. # Estimating the 95% CI using the 0.025 and 0.975 quantiles (two-sided)estimated_ci <-quantile(bootstrap_estimates, probs =c(0.025, 0.975))estimated_mean <-mean(original_scores) # Calculating the mean
Code
df = bootstrap_estimates |>as.data.frame()ggplot(data = df, aes(x = bootstrap_estimates)) +geom_bar() +theme_minimal() +theme(plot.title =element_text(hjust =0.5),text =element_text(size =12) ) +ggtitle("Sampling Distribution of Mini-Golf Scores for the Mean") +labs(x ="Bootstrap Sample Number (1 through n of number of bootstrap replicates)", y ="Mean of Sample")
Each of these is an estimate of the mean. This is a sampling distribution. We can now use this to determine our confidence intervals. We can calculate the standard error by calculating the standard deviation of this distribution or, we can do it using percentiles. If we’re using a two-sided test and 95% CIs then can take the 0.025 and 0.975 percentiles! Doing this, we now know our average score is 50.66 and our confidence interval is 49.44975, 51.64!
However, this is the mean. It doesn’t account for the number of obstacles on the course or if it was a weekend (perhaps we’d feel more rushed if we were playing on the weekend, making us play worse). So what if we want to fit a model and get 95% CIs for that model?
Mini-Golf: GLM Time
We’ll use a generalized linear model for our example. Side note: there is no rationale for picking a GLM, other than it’s a method that I’m familiar with. In reality, picking the model to use isn’t always so straightforward. Now, let’s simulate some data!
Code
# Setting seed for reproducibility, set.seed(123) # Setting seed for reproduceability, arbitrarily chosen in this case# Number of gamesn_games <-100# Number of obstacles on the course that gameobstacles <-round(runif(n_games, 5, 15))# Is it a weekend? Yes/no (1 if weekend, 0 otherwise)weekend <-sample(0:1, n_games, replace =TRUE)# Mini-golf scores, dependent on the number of obstacles and whether it was a weekend or notscores <-50+2* obstacles +5* weekend +rnorm(n_games, 0, 5)# Combining it all into a dataframe mini_golf_data <-data.frame(scores, obstacles, weekend)
We’ve got some data! Now, we want to calculate our 95% CIs from a GLM. To do this, we first need to sample some data, then fit a GLM to that new dataset and repeat, repeat, repeat as many times as we have chosen. So, let’s do it!
Code
# We'll use the tidymodels package here to get our multiple samples then fit a model to each sample. library(tidymodels)# First, let's get 1000 bootstrapped samples.boots <-bootstraps(mini_golf_data, times =1000, apparent =TRUE)# Now we'll create a function for fitting our model. In this case a GLMfit_glm <-function(df){# Fitting the glmglm(scores ~ obstacles + weekend, family =gaussian(link ="identity"),data = df )}# Now let's fit this model for each of our 1000 bootstrap samplesboot_glms <- boots %>% dplyr::mutate(model =map(splits, fit_glm),coef_into =map(model, tidy) )# Now we can pull out our coefficients boot_coefs <- boot_glms %>%unnest(coef_into)
Now we can calculate the 95% confidence intervals based on the same percentile method as before.
Code
# Now we can calculate the confidence interval by taking the 0.025 and 0.95 quantiles. int_pctl(boot_glms, coef_into)
Just like that, we have our 95% CIs for our terms. This method seemed to work pretty good and can be useful, so let’s just use it all the time! Well, not quite.
Why not use bootstrapping all the time?
“So what you’re telling me is I can just use bootstrapping all the time for every situtation?” Well, no. It is a useful tool but like all tools, whether statistical or not, there is a time and a place to use them. Would you use a hammer as a fly swatter? I guess you could, but why not just use a fly swatter.
Like any method, bootstrapping isn’t perfect. There are benefits and drawbacks. For example, it can give different results depending on the starting seed. It can also only draw observations from your data that has been observed. In our ice cream example, no bubble gum flavour would show because our bowl only has vanilla and chocolate. However, it’s not all bad. Bootstrapping can be a solution in a variety of situations and is quite flexible. It’s important to keep the benefits and drawbacks in mind when choosing it (these are only a few pros/cons).
What’s Next?
Bootstrapping is a wide area, this post was meant to be an introduction. There are a wide variety of use cases and types of bootstrapping, for example the bias-corrected and accelerated bootstrap. If you’re interested in learning more, there is an entire textbook on bootstrapping (Davison and Hinkley 1997). Happy bootstrapping!
References
Austin, Peter C. 2011. “An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies.”Multivariate Behavioral Research 46 (3): 399–424.
Davison, Anthony Christopher, and David Victor Hinkley. 1997. Bootstrap Methods and Their Application. Cambridge university press.
Gelman, Andrew, Jennifer Hill, and Aki Vehtari. 2020. Regression and Other Stories. Cambridge University Press.