Yes..well no…well kinda. DAG in this case, stands for Directed Acyclic Graph. It’s a graph that is directed and acyclic…alright that’s not much of an explanation. Let’s try again: a causal DAG is used to show the causal relationship between your variables.
Of course to show these variables, we are inherently making assumptions. For example, assuming that X causes Y. We always make assumptions in science, since the real world is complicated. These assumptions are sometimes made implicitly, making it difficult to address for reviewers or people reading your work.
Alternatively, if we show our assumptions explicitly then it makes the assumptions more obvious. To quote Miguel Hernán, since I couldn’t put it better myself, “Draw your assumptions before your conclusions”.
This post is meant to be an introduction
A minor note before we continue: this post is meant to be an introduction. DAGs can get quite complicated, especially is you add a lot fo variables, and have a variety of uses (i.e., selection of variables, identifying potential biases, guiding simulations, for missingness, etc). Future posts will delve more into these use cases but for now, it’s just meant to be a gentle intro.
Why should I?
A perfectly valid question at this point is “Why should I? I don’t need these. I know what assumptions I’m making”. While this may be true, a picture is worth a thousand words. It’s much, MUCH easier to identify biases visually than abstractly.
An equally, perhaps even more important point, is by using DAGs it is more clear for others to interpret/assess your assumptions. For example, confounding bias occurs when there’s a variable that affects both the exposure and the outcome. This is pretty straightforward to view.
A slightly more challenging example is collider bias. This occurs when ends of two different arrows meet at a variable. Collider bias is easy to identify visually but can be more difficult to identify abstractly, especially the more variables you add. Rather than just speaking, time for an example!
Does Coffee Increase My Alertness?
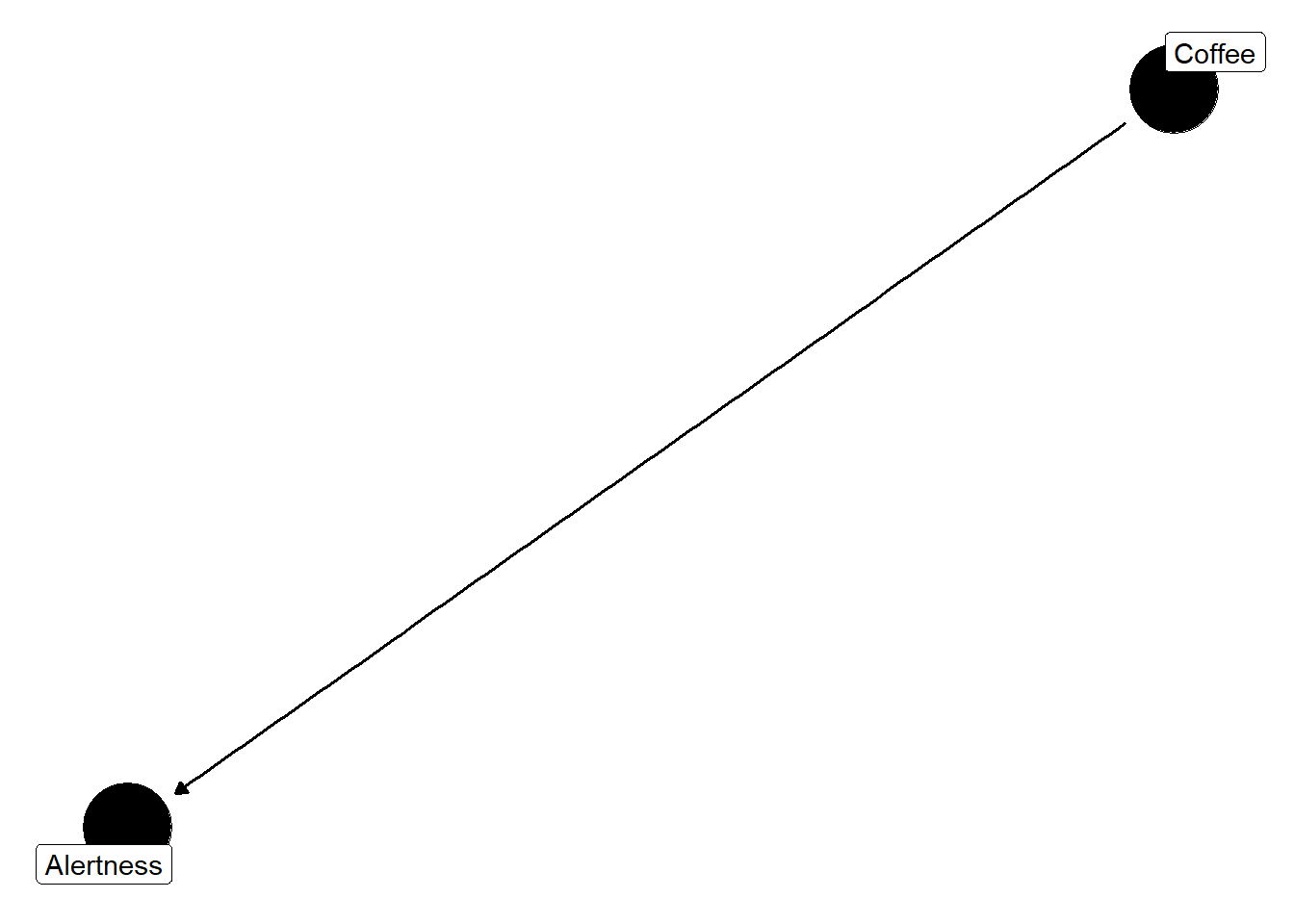
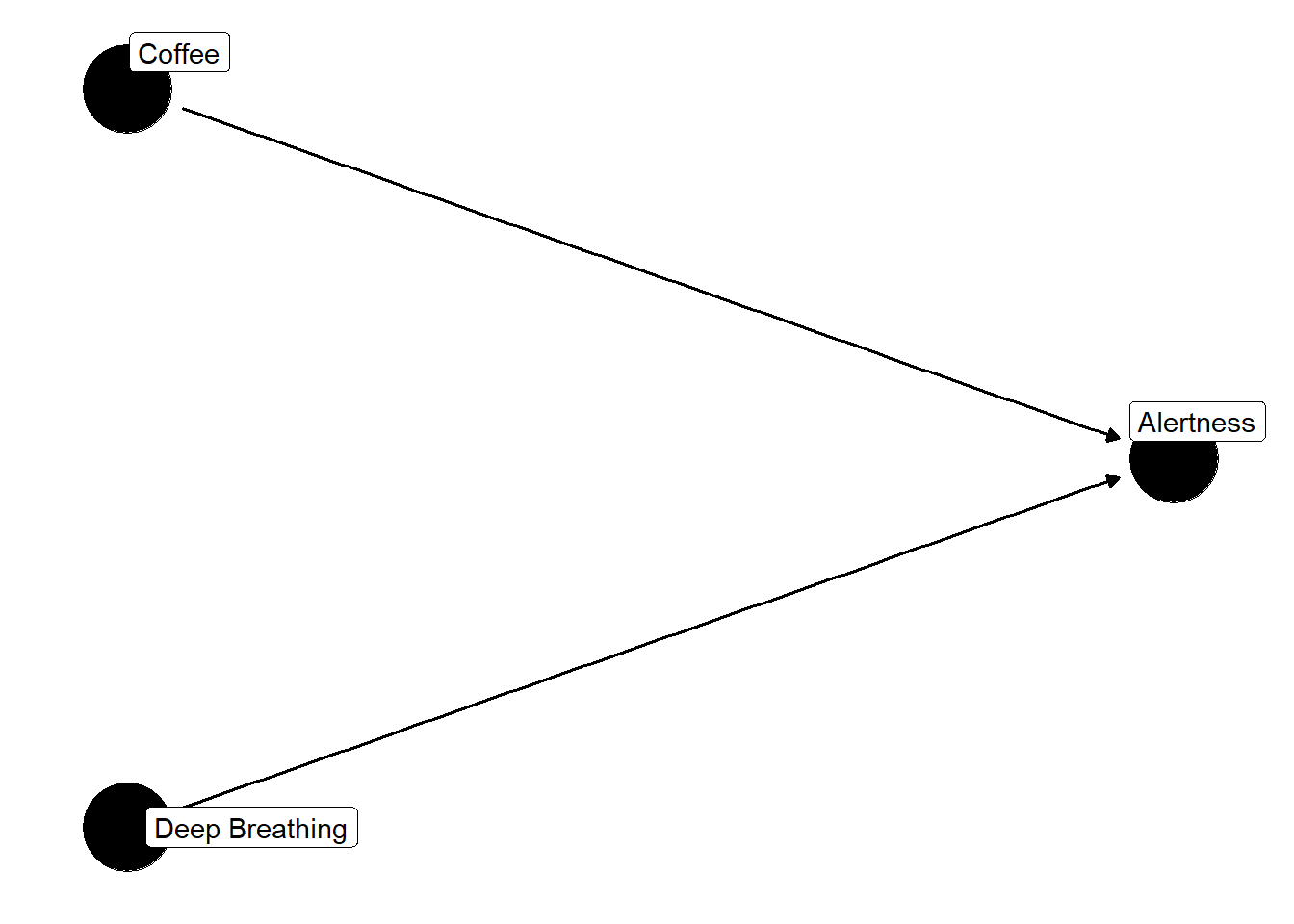
I’m an avid coffee drinker. I love hot coffee, iced coffee, cold brew, nitro cold brew…you name it, I’m in (unless it’s bad coffee). Something I often wonder is if drinking a lot of coffee actually increases my alertness or not. That is, does coffee cause increased alertness? Let’s start here. We’ll assume that coffee does cause alertness and draw a line between the two.
This looks great but there’s one glaring problem….there are many, many, MANY variables that affect coffee and alertness. How much you’ve slept, stress and hunger just to name a few. Not to mention that each of those variables are related. So our DAG needs some editing, but first we need to go over some assumptions or “house rules” per say.
Assumptions of DAGs
Let’s start with the acronym. They are called DAGs because they have a direction and cannot have a variable that causes itself, either directly or through another variable (Hernan and Robins 2021, 72).
Another key component is the causal Markov assumption, which put simply is that a variable is independent of any variable that it isn’t a cause for (for more details about this check out Hernan and Robins (2021), pp. 72). This assumption means that in a causal DAG, the common causes of any pair of variables in the graph must also be in the graph.
D-Separation
The d in d-separation stands for directionally separated. If all paths between two variables are blocked then we say that variables are d-separated (others they are d-connected). To decide if a path is blocked or open, we use the following rules (Hernan and Robins 2021, 78):
If no variables are being conditioned on, a path is blocked if and only if two arrowheads on the path collide at some variable on the path.
Any path that contains a non-collider that has been conditioned on is blocked.
A collider that has been conditioned on does not block a path.
A collider that has a descendant that has been conditioned on does not block a path.
Causal Graph Theory
There is some complex math, nonparametric structural equation models to be exact, behind these rules that I won’t go into here. If you are interested, I recommend checking out the work of Judea Pearl, or Chapter 6 of Hernan and Robins (2021).
To summarize d-seperation in a few sentences: a path is blocked if and only if, it contains a non-collider that has been conditioned on, or it contains a collider that has not been conditioned on and has no descendants that have been conditioned on (Hernan and Robins 2021, 78).
Water Flowing in a Pipe?
A useful way to think of this, to borrow a concept from Judea Pearl, is to think of water flowing in a pipe. For associations, this can flow both ways however when determining causality it cannot. Applying this thinking to the rules for d-separation think about it like water. If there is a collider, then water cannot flow like there is a dam. If the collider is conditioned on, its like we moved the dam and water can now flow.
Variables to Include
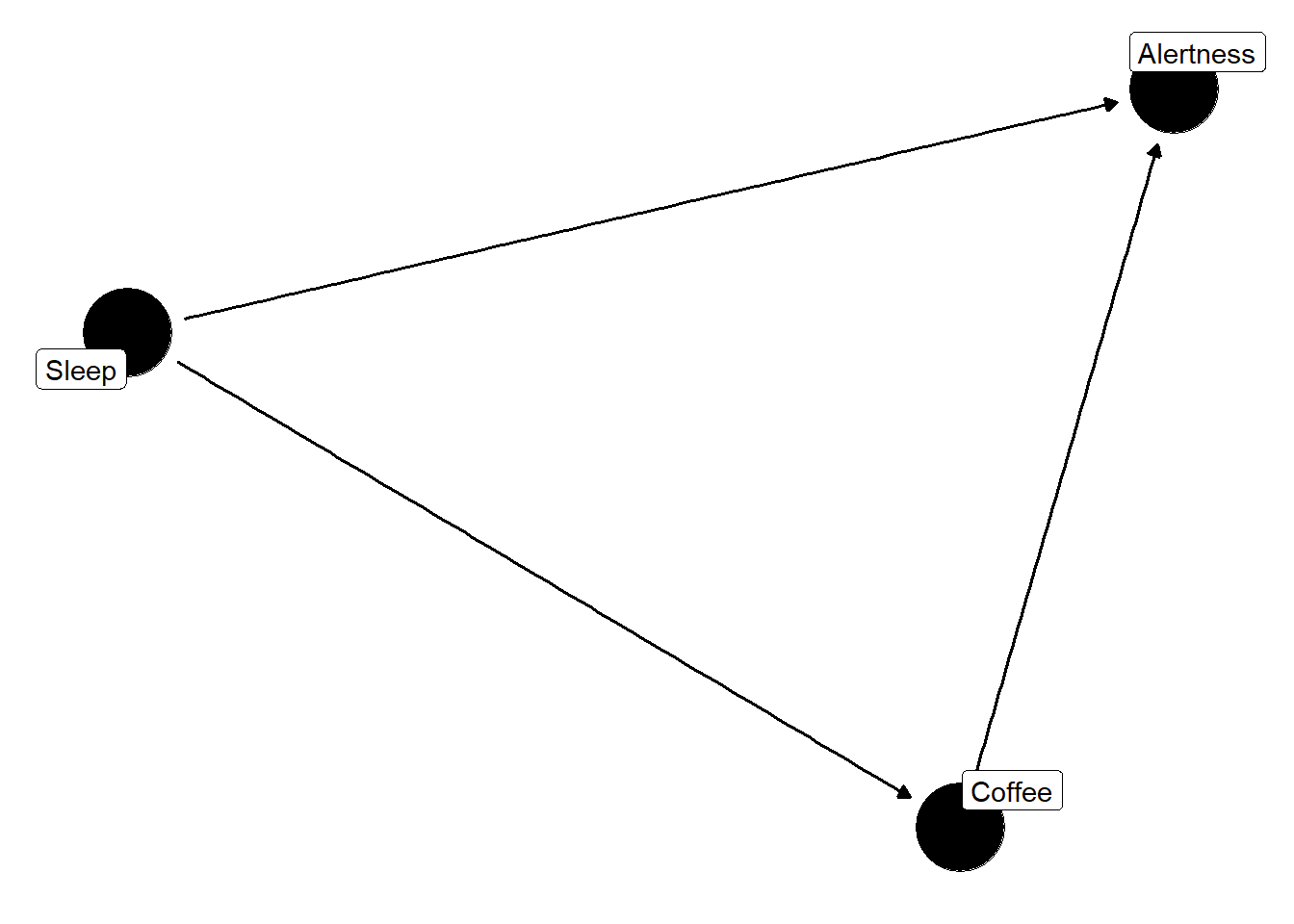
Let’s return to our original DAG with just coffee and alertness. We need to include some more variables here, but which ones? Let’s assume that we have some other things we think can be important to include: deep breathing and sleep.
Sleep definitely affects coffee consumption and alertness. This we need to add to our graph because it’s a common cause of coffee consumption and alertness.
Now, we can see here that sleep is a confounder. We can use our fancy new DAG to identify which variables are d-connected.
Code
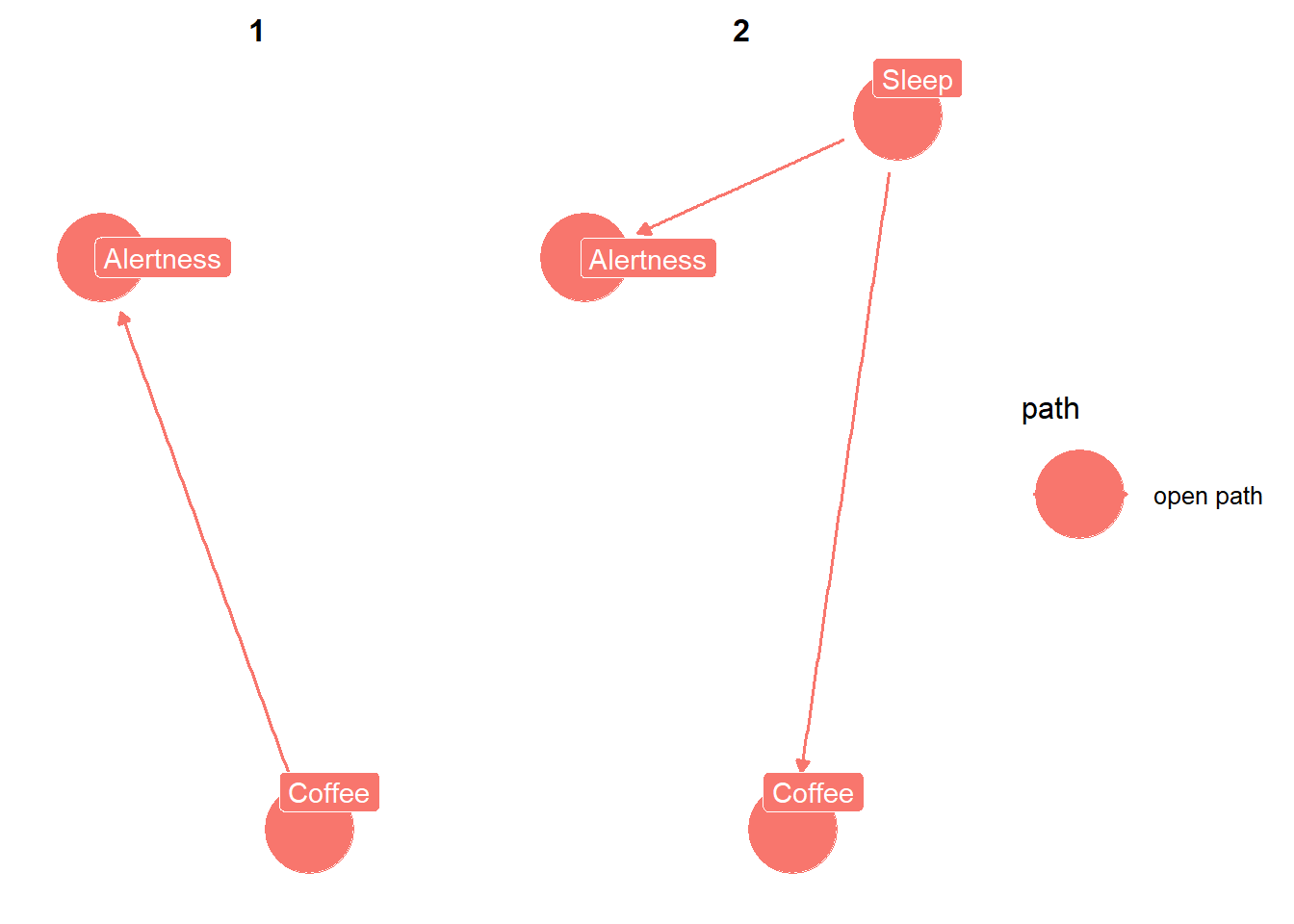
ggdag::ggdag_paths(coffee_dag, text =FALSE, use_labels ="label")
We can see that there are two paths between the variables. There is the first path between coffee and alertness, which we’d expect. The second path, is between coffee and alertness through sleep. This is not what we’d want and in this case would result in confounding bias if we don’t fix it. How do we fix it? By including it as an adjustment variable.
We can use the ggdag_adjustment_set() function from the ggdag package.
Code
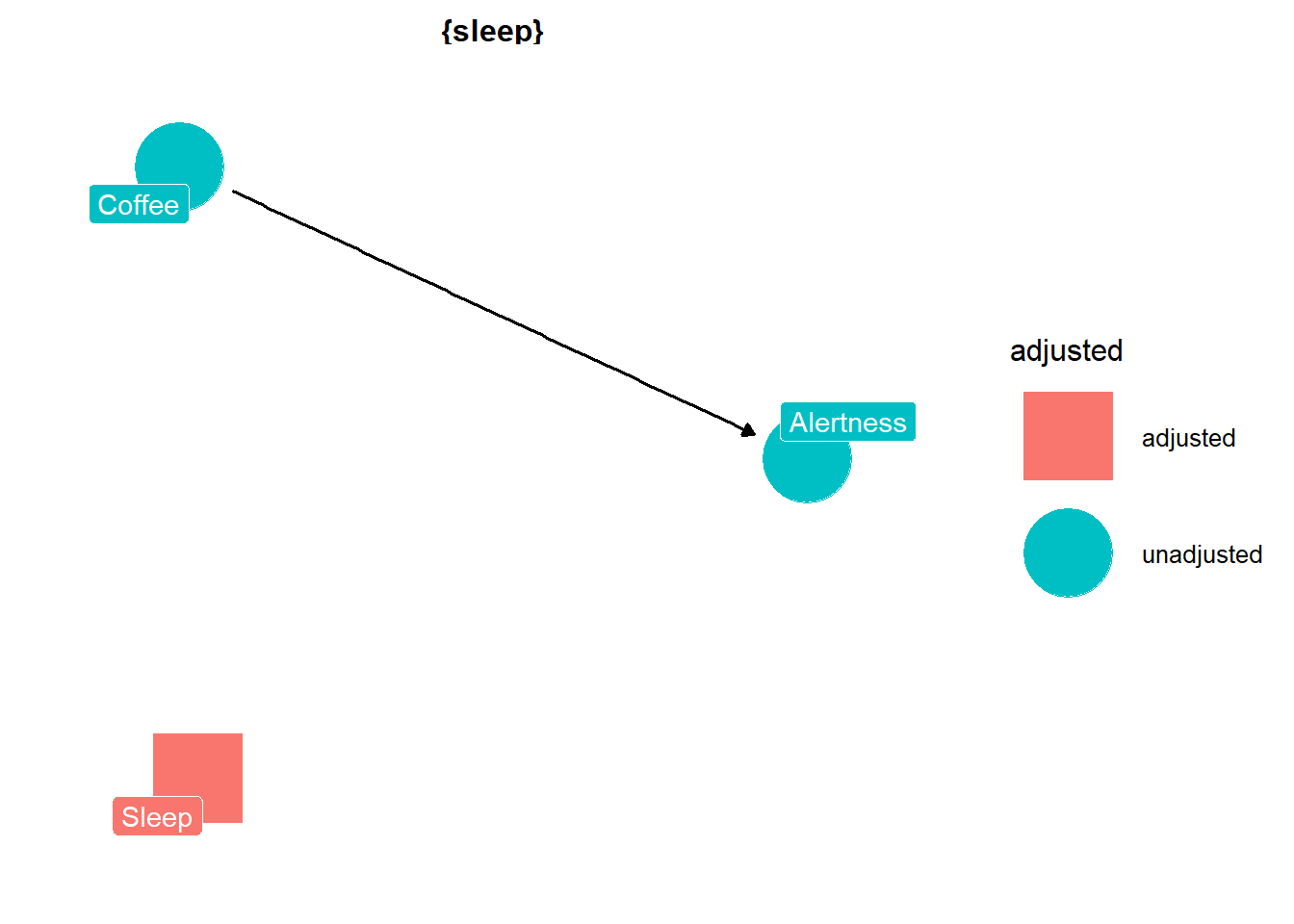
ggdag::ggdag_adjustment_set(coffee_dag, text =FALSE, use_labels ="label")
We can see that we need to adjust for sleep to close the opened path, which is what we’d expect. Now we can move onto deep breathing and find out whether we need to adjust for deep breathing or not.
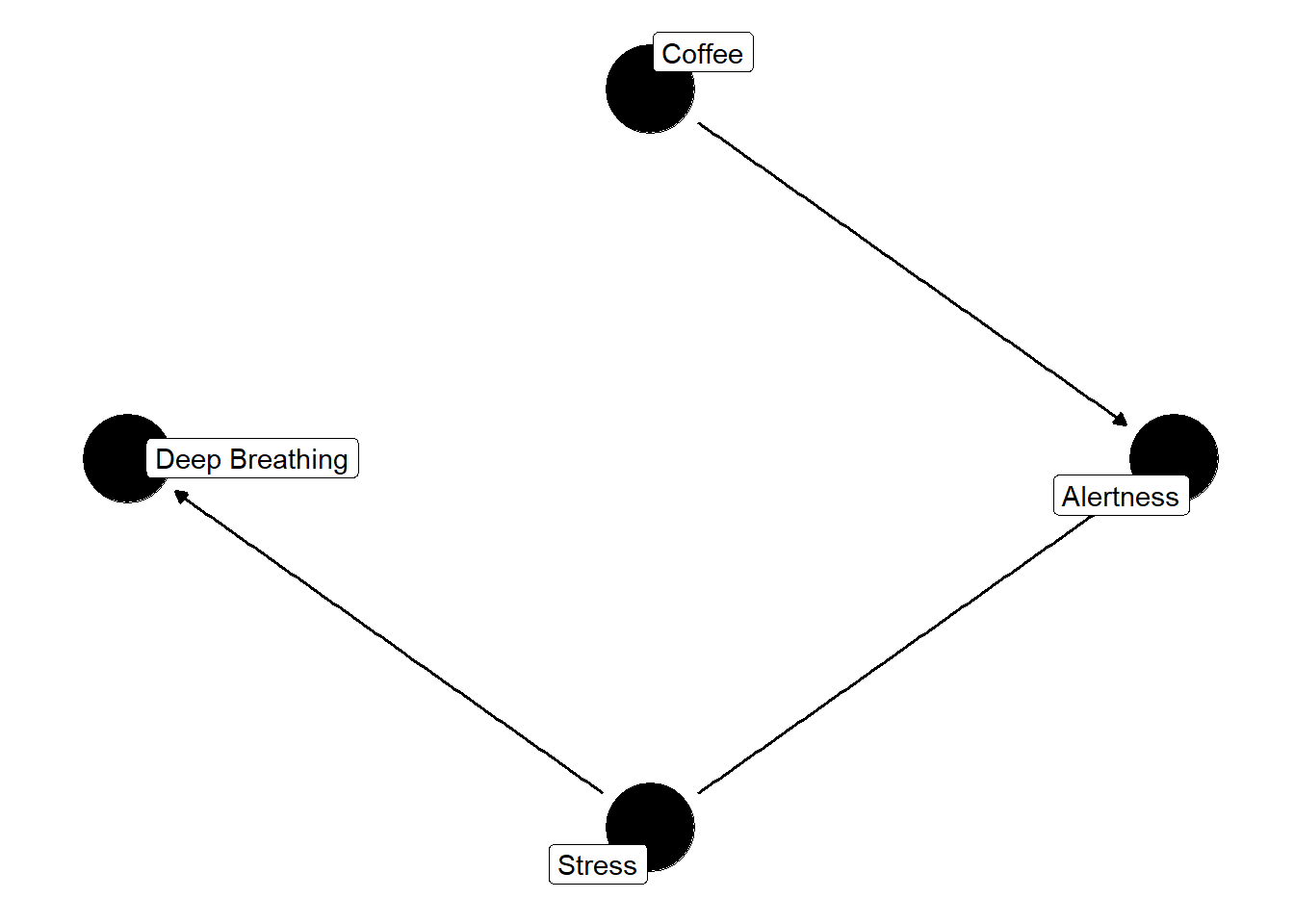
Deep breathing only affects alertness, or so we assume, this is an example of effect modification (spoiler alert: we can include if we want but the DAG is perfectly valid if not since deep breathing isn’t a common cause of A and Y)
We see that deep breathing affects alertness but not drinking coffee. Now, if we didn’t include deep breathing it would still be a valid causal diagram because deep breathing isn’t a common cause of coffee and alertness. We’d only need to include if it was part of our causal question (e.g., what is the average causal effect of coffee on alertness within levels of deep breathing?).
Now, another point is that including it in our causal diagram doesn’t distinguish which of the following three ways that alertness could modify the effect of coffee on alertness:
The causal effect of coffee on alertness is in the same direction in both deep breathing = yes and deep breathing = no
The direction of the causal effect of coffee on alertness in deep breathing = yes is opposite of that in stratum deep breathing = no
Coffee has a causal effect on alertness in one stratum of deep breathing but no causal effect in the other stratum.
In the DAG, it fails to distinguish which of these is the type of effect modification. Additionally, many effect modifiers do not have a causal effect on the outcome. Instead, they are surrogates for variables that have a causal effect on the outcome.
In this DAG, we see deep breathing is actually a surrogate for a variable that has a causal effect. Deep breathing is a surrogate effect modifier whereas stress is a causal effect modifier. Both of these are often indistinguishable in practice, so the concept of effect modification encompasses both (Hernan and Robins 2021, 81).
What’s Next?
Now you’ve grasped the basics of DAGs! You can use these to help answer all your causally related questions! Personally, I mostly use them for variable selection. It’s extremely helpful in analyses for real-world data when deciding which variables require adjustment. Hope you had as much fun reading it as I did writing it!
References
Hernan, M. A., and J. M. Robins. 2021. “What If - Causal Inference.” Textbook.