Simulating data is something that I’ve learned since graduating from my masters. It’s helped me tremendously with comparing methods and proving concepts to me. It’s also helped me improve my statistics knowledge.
I wanted to write this post to help anyone else who isn’t familiar with simulating data. Personally, I like to always see examples, below are a few:
Demonstrating bias by including/excluding a variable (confounder, collider, etc)
Comparing different methods (1:1 matching vs IPTW, etc)
Understand data generating mechanisms
Enough about how it’s helpful, how do we do it?!
NoteR Code
I primarily use R for coding, so this post focuses on using R. However, the methodology applies to whatever program you use for analysis. If you prefer to use MS Excel, you can do this using Excel as well, although it may not be the easiest. If you’re looking to learn R, I can’t recommend R for Data Science by Hadley Wickham enough (plus it’s free!)
How to Simulate Data in R
Before we dive into some R code, which I do love, it’s useful to first understand at a high level how this works. Before you scramble to close this, wait! I promise it isn’t going to be technical or boring….or at least I’ll try my best to not make it boring.
The way it works is we first assume a distribution (Gaussian, binomial, etc) that has some important pieces called parameters. You’re probably familiar with these for a Gaussian (sometimes called normal distribution), they’re the mean and standard deviation. These will determine the shape and probabilities of the distribution. So if we’re going to simulate a Gaussian distribution, we need to pick these numbers.
Once we have that information we can start picking out random samples. For example, if we know the average age is 60 and the standard deviation is 10, we can pick a person out from this group and find out their age is 78. Now, how do we do this in R?
NoteTime-to-Event Outcome
For simplicity, we’ll categorize outcomes into three categories as continuous, binary or time-to-event (TTE). This post won’t tackle TTE outcomes, but a future blog post will! It’s slightly more complicated, although nothing too tough to handle! Just would make for too long of a single post.
Continuous Outcomes
To simulate data in R, we can use a family of functions that start with r. For example, if we want to simulate data from a normal distribution we can use the rnorm function. Let’s simulate an exposure and outcome. But first, we need a question! Our question will be “Do more pacifiers in a baby’s crib cause them to sleep longer?”
We also need to decide what types of variables the exposure and the other variable are. Are they continuous, binary or some other type? For simplicity, we’ll assume both are variables that have a Gaussian/normal distribution. For our outcomes, it’s definitely continuous but how is it related to these other variables? We need an equation! We’ll use the following equation (that is completely made up): \(\text{hours slept} = 4 +0.5*\text{number of pacifiers} + 0.25* \text{age in months}\)
Code
library(tidyverse)set.seed(123) # we need to set a seed prior to simulating data. This allows us to replicate the data. For more details check out this blog post: [insert blog post about using different seeds for simulations]n.babies =128# note to get this value I used runif(1, min = 100, max = 500) then picked closest number divisible by 2num_pacifiers =rnorm(n = n.babies, mean =8, sd =3)age_months =rnorm(n.babies, mean =9, sd =2)hours_slept =4+0.5*num_pacifiers +0.25*age_months df =data.frame( num_pacifiers, age_months, hours_slept)
Okay, so we have our data. Now let’s do something with it! Let’s try fitting a generalized linear model (GLM)
Code
library(broom)mod =glm(hours_slept ~ num_pacifiers + age_months, family =gaussian(), # we know this because we simulated the data. In reality, you have to use a combination of visualizing the data, understanding the data generating mechanism (aka what distribution it came from and the best model fit (i.e., Poisson vs negative binomial))data = df )broom::tidy(mod)
Now, as you can see our estimates were pretty accurate. The intercept is 4, the coefficient for number of pacifiers is 0.5, and the coefficient for age is 0.25. These are exactly right, if we compare them to our equation above. Keep in mind, this makes sense because we included the two variables that we knew affected our outcome (hours slept).
Let’s try this again, but this time we’ll assume that pacifiers doesn’t matter, it’s only the age. What will happen if we adjust for both variables still? Let’s find out! We’ll try two models and compare them. One where we adjust for both variables and one where we adjust for only age.
Code
num_pacifiers =rnorm(n = n.babies, mean =8, sd =3)age_months =rnorm(n.babies, mean =9, sd =2)hours_slept =4+0.5*num_pacifiers +0.25*age_months df =data.frame( num_pacifiers, age_months, hours_slept)# Could alternatively try adjusting for the wrong variable (i.e., pacifiers but not age)mod1 <-glm(hours_slept ~ age_months, family =gaussian(link ="identity"), data = df)mod2 <-glm(hours_slept ~ age_months + num_pacifiers, family =gaussian(link ="identity"), data = df)broom::tidy(mod1)
Now you see how the impact of adjusting for a variable that doesn’t affect the outcome, at least in this case. For our model where we adjust for only age, the result is . When we adjust for the “correct” variables , we end up with a coefficient of 0.25.
This is how you simulate a continuous outcome, but what about a binary outcome?
NoteContinuous Distributions distributions
For the above example, we used a Gaussian/normal distribution. However, this doesn’t need to be the case. If we are dealing with age we may want to use a uniform distribution (using runif) and specifying the minimum and maximum. For example, if we are thinking of a variable where it may not make sense to have a value below a certain value (i.e., age where people are between 18 and 65).
For simplicity here, and because a number of statistical methods assume normality (cough also the central limit theorem cough), we will use rnorm.
Binary Outcomes
Simulating a binary outcome is similar to simulating a continuous outcome. A difference is that we need to convert the linear predictors (our equation) to the scale of choice. To do this, we’re going to use the logistic distribution, since we’re going to fit a logistic regression later. We can do this using the plogis function. Our question this time is “Does sleeping in a cold room cause a baby to sleep longer?”
Code
n.parents = n.babies*1.5coffee_consumption =rnorm(n = n.parents, mean =3, sd =0.5)hours_baby_slept =rnorm(n = n.parents, mean =4, sd =0.25)cold_room =rbinom(n = n.parents, size =1, prob =0.5)linpred =0.25*hours_baby_slept prob_tired =plogis(linpred) # converting the linear predictior to a probability on the logistic scaletired_parents =rbinom(n = n.parents, size =1, prob = prob_tired)df =data.frame( cold_room, coffee_consumption, hours_baby_slept, tired_parents)
Now we can fit a logistic regression model!
Code
mod =glm(tired_parents ~ hours_baby_slept,# tired_parents ~ coffee_consumption + hours_baby_slept + cold_room,family =binomial(link ="logit"), data = df)broom::tidy(mod)
Based on this, we can see that our model doesn’t give a great example but if we increase the sample size, what happens? What if we had 10 times the amount of people.
So if we include 10 times the people, our result gets closer! If we include 100 times the people, we’d expect it to get even closer.
NoteTTE Outcome
At this point, you may be expecting a section on simulating TTE outcome. This will be the topics of a future blog post, since it’s not quite as straight forward as continuous and binary outcomes.
You might be thinking “this is great and all, but how does this apply to causal inference?”
Simulating Causal Concepts
Causal Concepts
This blog is about causal inference! So let’s incorporate some into this post shall we? Instead of looking at GLMs, let’s demonstrate how unadjusted confounding can introduce bias. We’ll calculate bias as (Morris et al. 2019):
\[
E[\hat{\theta}] - \theta
\]
where \(E[\hat{\theta]}\) is the expected, or average, estimated value and \(\theta\) is the “actual” value. Later it will make more sense why we’re using the average. For now, just keep in mind it’s the average of all your estimated values. If you were to repeat this 1000 times, you’d have 1000 coefficients that you estimated and could take the average of those. Alright, let’s move along with an example!
ImportantCausal Estimand
We need to make sure we are looking at the same causal estimand when comparing methods. For example, if we want to compare propensity score matching to inverse probability weighting that would result in a different answer…because they target different estimands!
Showing Confounding
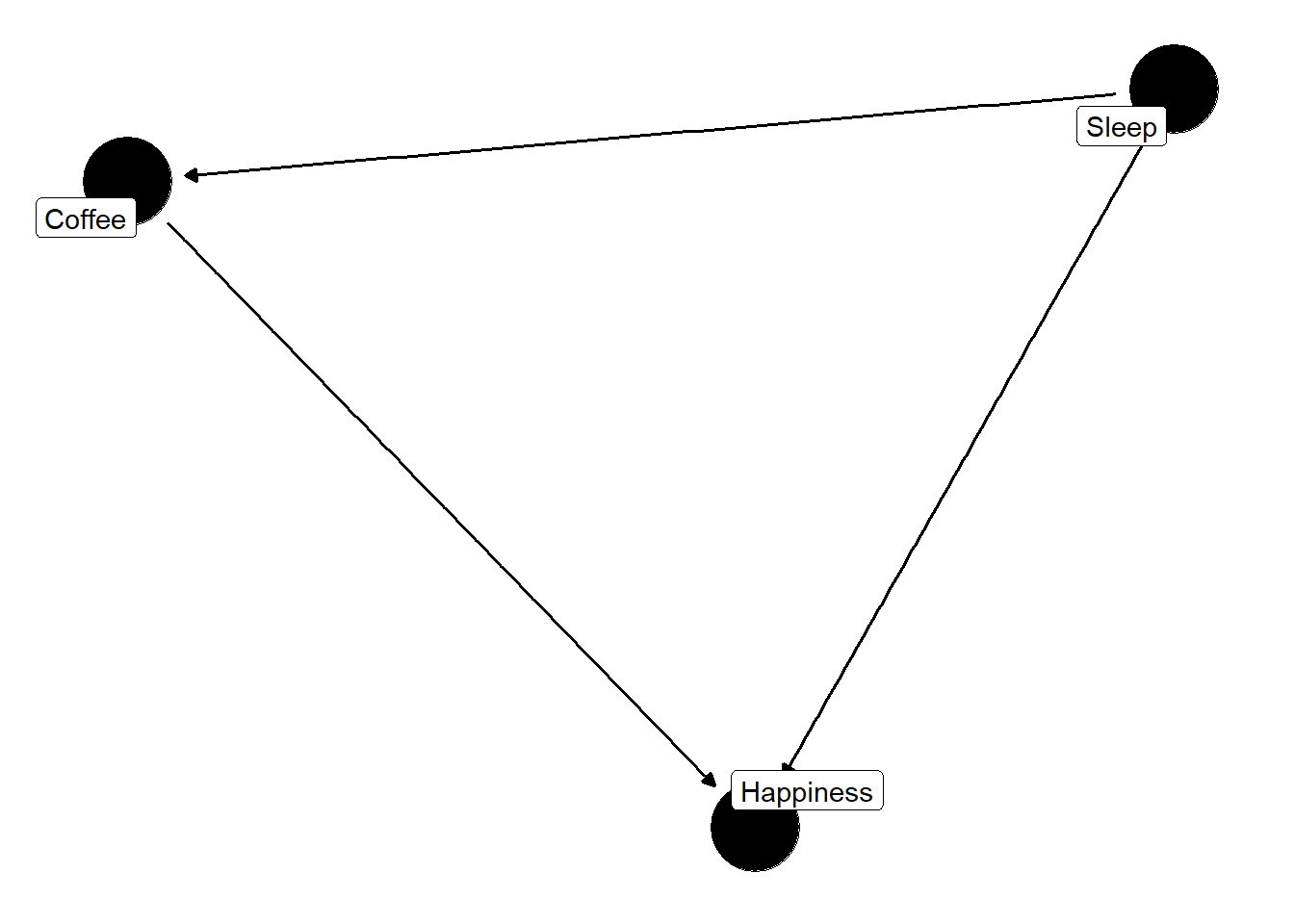
Let’s assume that we want to demonstrate how unadjusted confounding can be problematic. I’m an avid coffee lover, so we’ll use an example with coffee! Suppose that our research question is “Does consuming coffee cause you to be happy?” We can start by drawing a DAG with our three variables: happy, coffee and sleep.
Code
library(ggdag)
Attaching package: 'ggdag'
The following object is masked from 'package:stats':
filter
Now we have our DAG, you might be wondering how this has anything to do with simulating data. Well, it tells you which variables are related, and which ones cause the others. Time to simulate some data!
Code
set.seed(123) # Setting a seed for reproducibility# Number of observationsn <-1000# Simulating sleep hours (normal distribution with mean=7 and sd=1.5)sleep_hours <-rnorm(n, mean =7, sd =1.5)# Simulating coffee consumption based on sleep (negative correlation: less sleep -> more coffee)coffee_consumption <-5-0.5* sleep_hours +rnorm(n, mean =0, sd =1)# Simulating happiness based on both sleep (positive correlation: more sleep -> more happiness)# and coffee consumption (positive correlation: more coffee -> more happiness)happiness <-rbinom(n = n, size =1, prob =plogis(0.3* sleep_hours +0.2* coffee_consumption +rnorm(n, mean =0, sd =1)))# Creating a data frame to hold the variablesdf <-data.frame(sleep_hours, coffee_consumption, happiness)head(df)
Now we have our data. To show what happens when you don’t adjust for a confounder, we’ll fit two models: 1) not adjusting for the confounder, 2) adjusting for the confounder. We know what the “truth” is, because we decided it! The “truth” is a coefficient of 0.2. Let’s see what happens
Now we have our two models, we can calculate bias for each of these models. As we can see, the bias from model one (-0.1397736) is more than the bias from model two (0.0277288). But how can we trust this? We only did it once. What if a sample of the same size (N = 250) gave a different answer? To account for this, we need to repeat this multiple times. So, let’s do that! Let’s repeat it a thousand times
Code
set.seed(123) # Setting a seed for reproducibilitysimulation <-function() {# Number of observations n <-250# Simulating sleep hours (normal distribution with mean=7 and sd=1.5) sleep_hours <-rnorm(n, mean =7, sd =1.5)# Simulating coffee consumption based on sleep (negative correlation: less sleep -> more coffee) coffee_consumption <-5-0.5* sleep_hours +rnorm(n, mean =0, sd =1)# Simulating happiness based on both sleep (positive correlation: more sleep -> more happiness)# and coffee consumption (positive correlation: more coffee -> more happiness) happiness <-rbinom(n = n, size =1, prob =plogis(0.3* sleep_hours +0.2* coffee_consumption +rnorm(n, mean =0, sd =1)))# Creating a data frame to hold the variables df <-data.frame(sleep_hours, coffee_consumption, happiness)# Building the models mod1 <-glm(formula = happiness ~ coffee_consumption,family =binomial(link ="logit"),data = df) mod2 <-glm(formula = happiness ~ coffee_consumption + sleep_hours,family =binomial(link ="logit"),data = df)# Calculating the biases coef1 <-coef(mod1)[2] coef2 <-coef(mod2)[2] coef_results <-data.frame( coef1, coef2 )# Returning the biases as a named vectorreturn( coef_results )}# Replicating the simulation 1000 timesoutput_list <-replicate(n =1000, expr =simulation(), simplify =FALSE) # Bind all data frames in the list into a single data framedf.out <-do.call(rbind, output_list)bias1 =mean(df.out$coef1) -0.2bias2 =mean(df.out$coef2) -0.2
Remember the mean from earlier? This is where it comes back up. We’ll use the mean of all of these 1000 estimates of our treatment coefficient. So how do they compare, well -0.216 is higher than -0.018 when you look at the absolute value. This is what we’d expect when dealing with a confounder that hasn’t been adjusted for.
NotePicking a number of simulations
For our example we picked 1000 repetitions but where did this number come from? Truthfully, it was completely arbitrary. In practice, we need to carefully choose how many we need. I highly suggest Morris et al. (2019) as a reference for more information if you need to pick the number of simulations.
Other Use Cases
We can use this to show other concepts as well, test new ideas or learn methods ourselves. Recently, I used it to demonstrate to myself the bias when you include a collider. Another example, that I’m currently exploring comparing entropy balancing and inverse probability weighting (in terms of mean squared error, bias, etc). Hopefully you found this post helpful! Would love to hear any situations where you are using simulation. Happy simulating!
References
Morris, Tim P, Ian R White, and Michael J Crowther. 2019. “Using Simulation Studies to Evaluate Statistical Methods.”Statistics in Medicine 38 (11): 2074–102.